City College, Spring 2019
Intro to Data Science
Week 13: Concepts and Solutions in Big Data
May 13, 2019Today's Agenda
- What is Big Data?
- Frameworks for Handling Big Data
- Tools for Processing Big Data
- Case Studies
Final Project: Due Wednesday, May 15 by 6:30pm
- A write up of 1,200 to 1,600 words and at least 2 data visualizations on Medium.
- A fully documented repository of code on GitHub.
- An 8-10 minute class presentation with slides and visuals.
- A short project review from each team member summarizing each teammates contributions to the group effort and lessons learned through the project.
Send links to Github and Medium to itds.ccny@gmail.com by 6:30pm on Wednesday May 15.
What makes big data "big"?
The Age of Big Data
Over the past twenty years, data has become dramatically cheaper to:
- Collect
- Store
- Process
What makes big data "big"?

Variety of Data
- Covered in class:
- Continous / categorical / binary
- Text as data
- Survey data
- Not covered in class:
- Photos, video
- Geospatial data - mobile trace, fitness trackers, etc.
- Website tracking data
Velocity of Data
- Concepts:
- 24/7 news cycles, accessibility, service
- Mobile first technology
- On-demand economy
- Requirements:
- Real time alerts
- High volume, low latency processing
Volume of Data
- Concepts:
- Terabytes, petabytes, and exabytes
- On-premise vs. off-premise storage
- Distributed computing
- Examples:
- Click data
- Search histories
- Large collections of text, photos, or videos
My Take
Big data is data that can't be easily stored and processed on a single machine.
- With roughly 20,000 sales listing a month, most of my work at StreetEasy is not big data.
- An exception: dozens or hundreds of individual users will look at a single site, making our activity data much trickier to deal with .
Processing Big Data
Key Concepts
- Distributed Storage and Computing
- Streaming and Batch Processing
- Queues
Distributed Storage and Computing
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Source
Storage: HDFS
HDFS = Hadoop Distributed File System
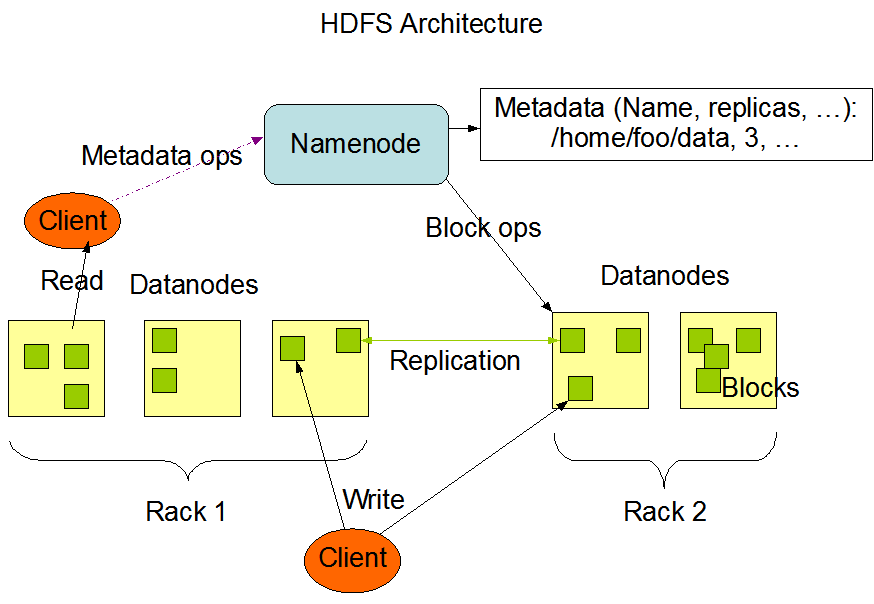
Source
Storage: AWS S3
S3 = Simple Storage Service
How do we read large data sets stored remotely?
One row at a time!
Python Generators
Generators are functions that can be paused and resumed on the fly, returning an object that can be iterated over. Unlike lists, they are lazy and thus produce items one at a time and only when asked. So they are much more memory efficient when dealing with large datasets.
def fibonacci():
x, y = 0, 1
while True:
yield x
x, y = y, x + y
MapReduce
- MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
- Map stage: each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of redundant input data is processed.
- Shuffle: worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
- Reduce: worker nodes now process each group of output data, per key, in parallel.
MapReduce

MapReduce
Example: Counting bi-grams in documents
- Map stage: Within each document set, extract and count each set of bi-grams as key-value pairs. Ie - ("hot dog", 3) ("potato salad", 1) ("fried chicken", 3).
- Shuffle: sort map key-value output across key values, distribute to workers.
- Reduce: sum value counts so that each bi-gram has a single count for all documents.
Application: Google n-grams
Lots of tools can save us time
Database Tools



Processing Tools: ML

Spark use case at Facebook
Processing Tools: Handling Streams
Processing Tools: Ecosystems

Get this work requires teamwork!
- Data Scientists
- Data Engineers
- Dev Ops
- Product Managers
- Machine Learning Engineers, Applied Scientists, etc.
What can big data analytics enable?
- Better analysis and predictions of rare events
- More personalized services for individuals
- Broader feature sets for more traditional problems
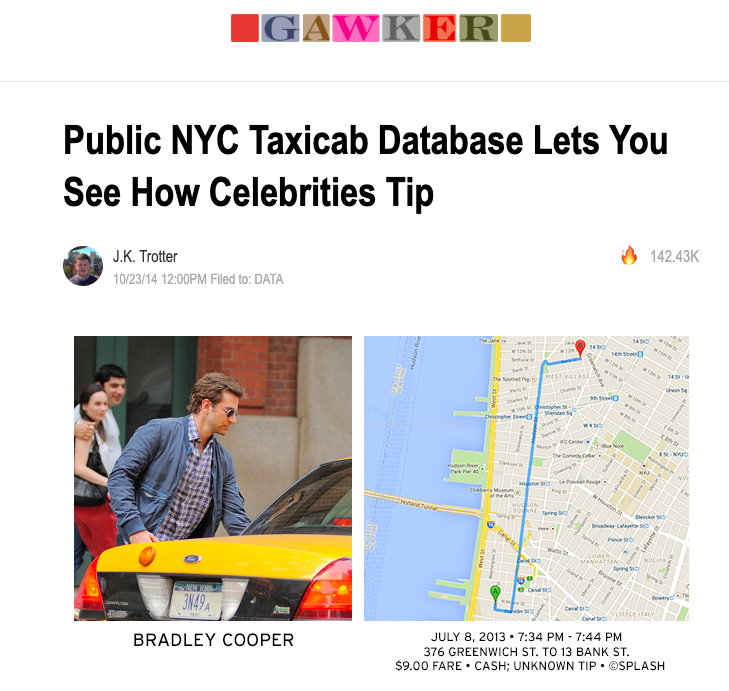
Example: NYC Taxi Data
- ~8 million trips per month
- Flat files stored in AWS S3
A cool demo using taxi data.
This Can Go Wrong